AI Newsletter - April 2026

April 2026 felt like the “agentic era” becoming operational reality: models got better at staying on task for hours, product teams shipped orchestration layers into real workflows, and the cybersecurity world got a preview of what happens when vulnerability discovery scales like software.
Here is your monthly round-up of the most significant developments in AI.
Core AI Models & Tech
OpenAI GPT-5.5
OpenAI introduced GPT‑5.5 as a faster, more capable model aimed at complex, multi-part work—especially agentic coding and tool-using workflows—while keeping latency competitive with prior generations.
Read more →
Claude Opus 4.7
Anthropic released Claude Opus 4.7 with notable gains on the hardest software engineering tasks, stronger instruction-following, and higher-resolution vision—plus new “effort” controls for tuning reasoning/latency in real deployments.
Read more →
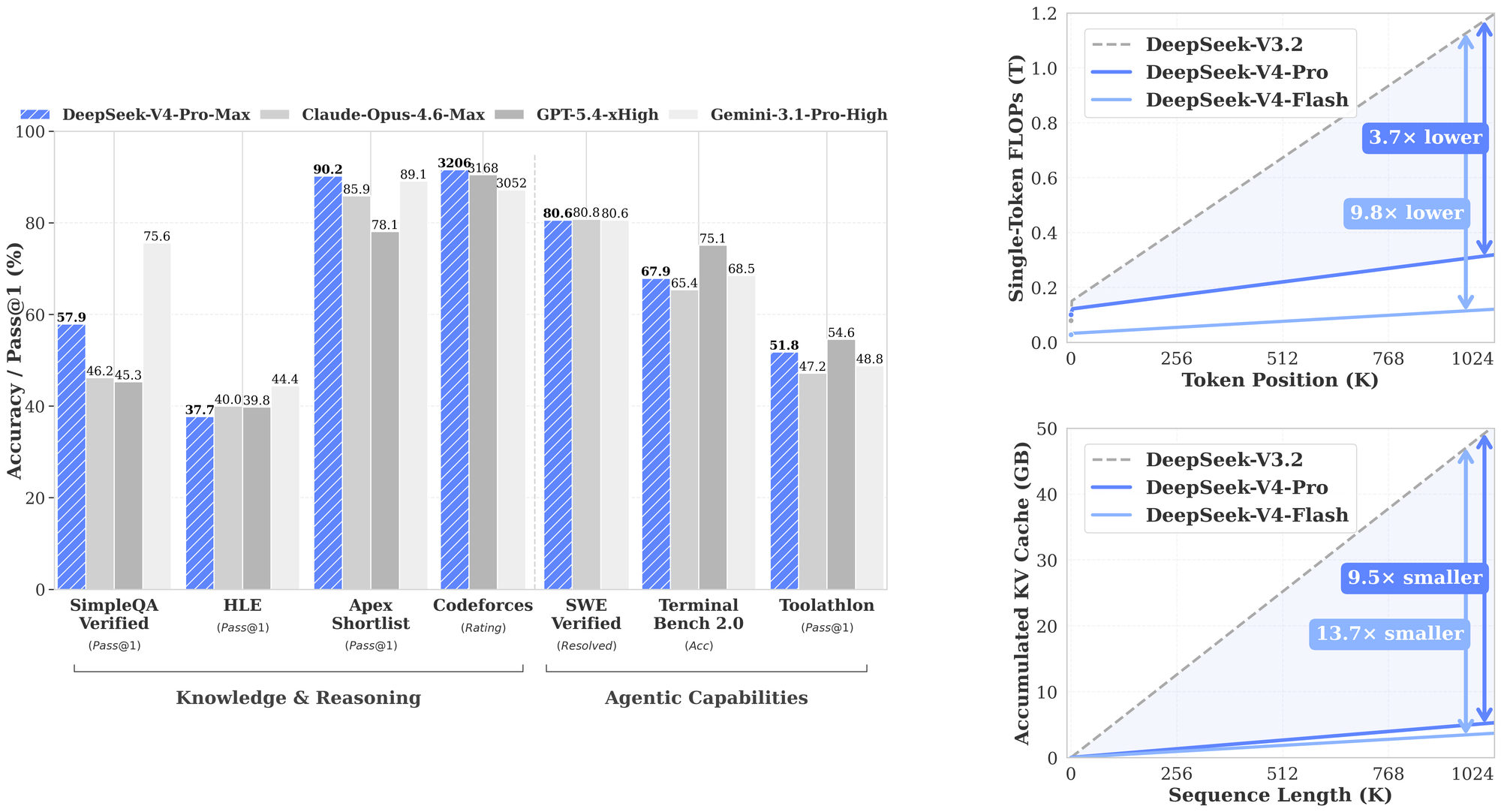
DeepSeek-V4 (Million-token context)
DeepSeek previewed V4 Pro/Flash MoE models supporting a 1M-token context window, backed by architectural changes designed to make ultra-long context tractable (dramatically lower FLOPs/KV-cache in the 1M setting).
Read more →
Kimi K2.6 (Open-source coding + agent swarms)
Kimi open-sourced K2.6, positioning it around long-horizon coding reliability and “agent swarm” orchestration—scaling to hundreds of sub-agents and thousands of coordinated steps for end-to-end runs.
Read more →
GLM-5.1 (8-hour long-horizon runs + MCP)
Z.AI’s GLM‑5.1 is positioned as a flagship for long-horizon tasks (up to ~8 hours), with large context, function calling, structured output, and explicit support for integrating external MCP tools and data sources.
Read more →
Gemma 4
Google DeepMind’s Gemma 4 highlights “agentic workflows” (including function calling), multimodal reasoning, and efficient architectures that keep strong capabilities deployable on more accessible hardware.
Read more →
Qwen3.6-Plus (1M context + “preserve_thinking”)
Qwen launched Qwen3.6-Plus with a 1M context window, stronger agentic coding/tool use, and an API feature (preserve_thinking) intended to improve multi-step consistency for agent workloads.
Read more →
AI Products & Tools
Qwen Studio
Qwen Studio is positioned as a full “AI workbench” (chat + multimodal + search + tool use + artifacts), while the Qwen team simultaneously pushes open models (e.g., Qwen3.6-27B) into the broader dev ecosystem.
Read more →
Prompt guidance for GPT-5.5 (Outcome-first prompting)
OpenAI published updated prompt guidance: shorter, outcome-oriented prompts; avoid legacy over-specification; explicitly define personality + collaboration style; and consider streaming preambles to improve perceived responsiveness.
Read more →
Perplexity “Personal Computer”
Perplexity began rolling out “Personal Computer,” pitching a local-machine orchestrator that can work across files, apps, connectors, and the web—trying to make agentic workflows feel like a managed, auditable teammate rather than a black box.
Read more →
Google Cloud Next ’26: Gemini Enterprise Agent Platform
Google Cloud doubled down on enterprise agent infrastructure: an end-to-end “Gemini Enterprise Agent Platform,” long-running background agents, an Agent Inbox for oversight, and new infra (TPUs/network/storage) to support “millions of agents.”
Read more →
Research & Breakthroughs
Muse Spark (Meta Superintelligence Labs)
Meta introduced Muse Spark as a natively multimodal reasoning model with tool use and multi-agent orchestration—plus a “Contemplating mode” that runs multiple agents in parallel to push hard-reasoning performance.
Read more →
The 2026 AI Index Report
Stanford HAI’s AI Index emphasized that frontier capability is accelerating (not plateauing), that the U.S.–China performance gap has effectively closed, that adoption is spreading rapidly, and that responsible-AI measurement/reporting still lags the capability curve.
Read more →
Ethics, Society & Impact
Deezer: AI-generated tracks now ~44% of daily uploads
Deezer reported ~75,000 AI-generated tracks uploaded per day (~44% of daily uploads) and described measures like labeling, removing AI tracks from recommendations, and demonetizing suspected fraudulent streaming—an early example of platforms needing “content authenticity ops.”
Read more →
Claude Mythos Preview: So good that you cannot touch (yet!)
Anthropic’s Red Team write-up details testing suggesting Mythos Preview can identify and exploit zero-days across major OSes/browsers, and argues for coordinated defensive action while disclosure is constrained by patch status.
Read more →
Anthropic announced Project Glasswing, bringing major tech/security partners together to use Claude Mythos Preview defensively—scanning critical and open-source software, sharing learnings, and trying to get ahead of an era where vulnerability discovery/exploitation can scale.
Read more →
Mythos in the wild: patch floods + coordination challenges
An FT report captured the operational downside of “AI at vulnerability-discovery scale”: a flood of patches, potential downtime tradeoffs for critical infrastructure, and a renewed push for public–private coordination as similar capabilities spread.
Read more →